In dit artikel nemen we een duik in de kosten van drie veelgebruikte oplossingen in Azure die Apache Spark gebruiken:
- Azure Data Factory
- Azure Databricks
- Azure Synapse Analytics
Eerst leggen we uit hoe deze oplossingen werken, en hoe ze gebruik maken van Apache Spark. Daarna gaan we dieper in op de kostenopbouw. Zo kunnen we uiteindelijk de hamvraag beantwoorden: welke tool is het duurst? Spoiler: het hangt van heel veel factoren af!
Alle in dit artikel geschatte kosten zijn gebaseerd op de Azure Pricing calculator. De Pricing Calculator is een gratis service van Microsoft waarmee je inzicht kunt krijgen in de prijs van verscheidene tools op Azure.
Wat is Apache Spark?
Apache Spark is een multi-language (big) data processing programmeertaal die gebruik maakt van in-memory computing. Apache Spark kan worden gebruikt voor het oplossen van data engineering, data science, en machine learning vraagstukken. Het kan bijvoorbeeld worden gebruikt voor het aggregeren, transformeren en opschonen van grote hoeveelheden data. Apache Spark kan, in theorie, op elke computer worden geïnstalleerd. Maar, in de cloud maken we gebruik van clusters om applicaties van de nodige rekenkracht te voorzien. Op Azure wordt Apache Spark gebruikt in verscheidene tools, waaronder Azure Data Factory, Azure Databricks, en Azure Synapse Analytics.
Wil je weten wanneer je switch moet maken van de GUI naar het zelf programmeren van Apache? In dit artikel leggen we het uit: "Data Factory vs. Databricks: Wanneer je liefde voor data wat (Apache) Spark mist.
Azure Data Factory: een overzicht
Azure Data Factory (ADF) is een volledig beheerde, serverloze data-integratiedienst. ADF kan worden gebruikt voor het inladen en transformeren van data. In ADF maak je gebruik van een grafische gebruikersinterface (GUI). ADF kan standaard verbinding maken met meer dan 90 ingebouwde gegevensbronnen. Deze gegevensbronnen kunnen op een eenvoudige manier met de hand worden geconfigureerd. Binnen ADF kun je op meerdere manieren data integreren, maar het zijn de Data Flows die gebruik maken van Apache Spark.
ADF Data Flows
Data Flows worden gebruikt om datatransformaties op een visuele manier te ontwerpen. Data Flows zijn handig voor gebruikers die wel gebruik willen maken van Apache Spark, maar die niet willen of kunnen programmeren.
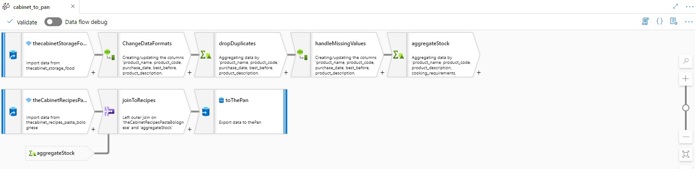
Voorbeeld van een dataflow.
Data Flows draaien op een zogenaamde Data Flow Runtime. De Data Flow runtime levert de rekenkracht die Apache Spark nodig heeft om transformaties uit te voeren. Data Flow Runtimes zijn er in twee verschillende smaken: General Purpose en Memory Optimized. General Purpose runtimes zijn goed voor algemene gebruikssituaties. Memory Optimized runtimes bieden de beste prestaties, wat ze geschikt maakt voor grotere datasets.
ADF kosten:
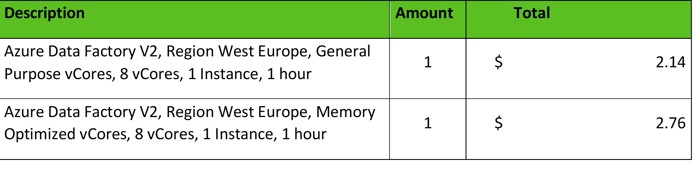
Voorbeeld ADF-prijs geschat op 25-03-2022. Voor de huidige prijslijst kan je de Pricing Calculator raadplegen.
Andere activiteiten, zoals bijvoorbeeld monitoring, zijn in ADF apart geprijsd. Dit betekent dat de werkelijke kosten hoger zullen zijn dan hierboven aangegeven.
Azure Databricks: een overzicht
Azure Databricks helpt je bij het oplossen van Data Science, Data Engineering, Machine Learning, en Business Intelligence use cases. Azure Databricks stelt gebruikers in staat om zelf Apache Spark code te schrijven. Dit is in tegenstelling tot ADF, waar de gebruiker data transformaties met de hand configureert. Apache Spark wordt in Azure Databricks uitgevoerd op Apache Spark clusters. Clusters kunnen gekoppeld woorden aan notebooks, waar de geschreven Apache Spark code staat. Clusters zijn het brein van de operatie, en bieden de rekenkracht die nodig is om Apache Spark te draaien. Azure Databricks ondersteunt meerdere talen zoals Python, Scala, R, Java en SQL.
Azure Databricks Notebooks
Een notebook is een web-based interface waarin een gebruiker code schrijft. Apache Spark-code wordt in zogenaamde 'cellen' geplaatst.
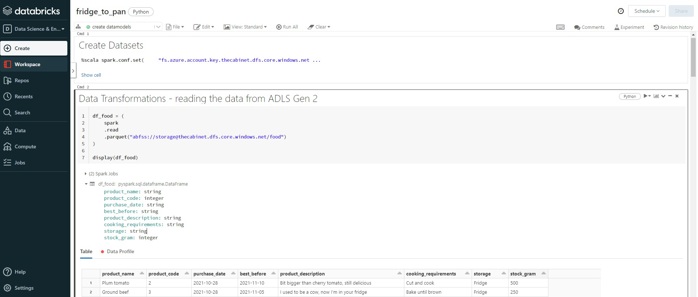
Voorbeeld Azure Databricks notebook
Bij het opzetten van een cluster heeft de gebruiker veel opties. Zoals je je kunt voorstellen, zijn alle opties iets anders geprijsd. Om de prijsstelling wat eenvoudiger te maken, krijgt elk Azure Databricks cluster een aantal Databricks Units (DBU) toegewezen. Des te meer DBU’s, des te hoger de rekening. Zoals Microsoft het stelt: "Een DBU is een eenheid van verwerkingscapaciteit, gefactureerd per seconde. Het DBU-verbruik is afhankelijk van de grootte en het type instantie waarop Azure Databricks draait". Settings die invloed hebben op het DBU-gebruik zijn onder andere: of de Azure Databricks instantie Standard of Premium is, het aantal Workers op het cluster, het Worker type, en het Driver type. Meer informatie over cluster configuratie kan hier worden gevonden.
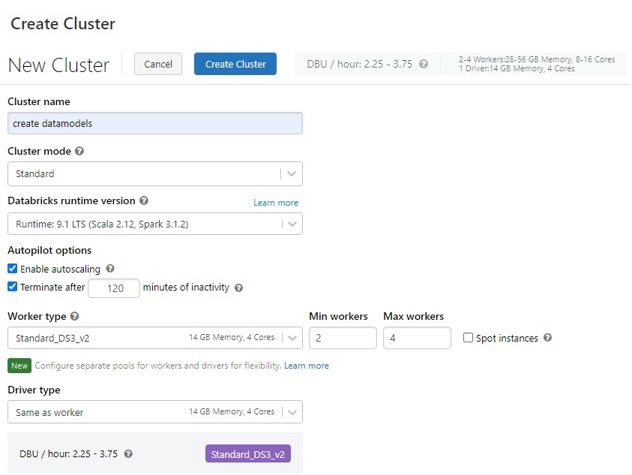
Voorbeeld Azure Databricks cluster
Azure Databricks kosten:
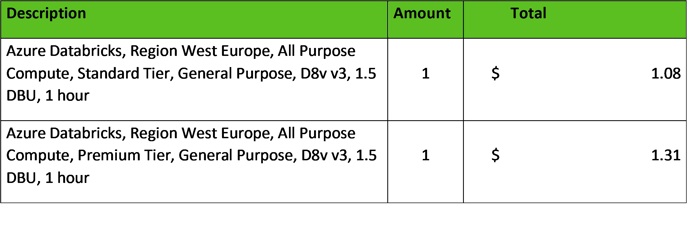
Voorbeeld Azure Databricks pricing geschat op 25-03-2022. Voor de huidige prijslijst kan je de Pricing Calculator raadplegen.
Azure Synapse Analytics: een overzicht
Azure Synapse Analytics, voorheen bekend als Azure SQL Data Warehouse, is veel meer dan een gewone SQL oplossing. Deze uitgebreide tool combineert Apache Spark voor big data analyse, dedicated en serverless SQL pools voor het data warehouse, Data Explorer voor log en time series analyse, en Pipelines voor ETL/ELT processen. Azure Synapse Analytics maakt gebruik van Apache Spark in zowel Pipelines als de Spark pools. Azure Synapse Analytics ondersteunt meerdere talen, waaronder Python, Scala, .NET, en Spark SQL.
Gezien de grote gelijkenissen tussen Azure Synapse Analytics Pipelines en ADF Data Flows in zowel functionaliteit als kosten, zal dit artikel Azure Synapse Analytics Pipelines niet apart behandelen.
Azure Synapse Analytics Notebooks
Een notebook in Azure Synapse Analytics is, net als bij Azure Databricks notebooks, een web-based interface. In een notebook kan de gebruiker cellen aanmaken waarin Apache Spark code kan worden geplaatst. Deze code kan worden uitgevoerd nadat een Spark Pool is aangemaakt en gekoppeld aan het desbetreffende notebook. Spark Pools zijn het brein van de operatie en bieden de rekenkracht die nodig is om Apache Spark code uit te voeren.
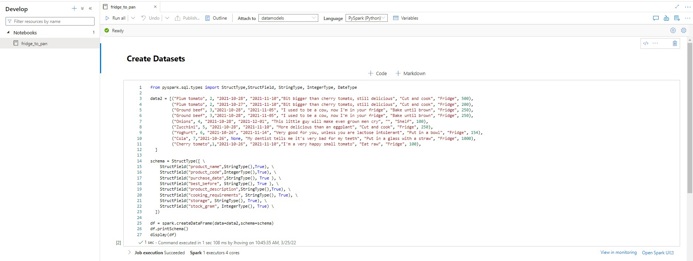
Voorbeeld Azure Synapse Analytics notebook
Het aanmaken van Spark Pools is vergelijkbaar met het creëren van Azure Databricks clusters. Over het algemeen heeft de gebruiker iets minder opties om uit te kiezen dan in Azure Databricks. Zo kun je in Azure Synapse Analytics bijvoorbeeld kiezen uit Apache Spark 3.1 en 2.4. Azure Databricks biedt meer opties, variërend van Apache Spark 3.2.1 tot 2.4.5. Instellingen die van invloed zijn op de kosten zijn onder meer of de Spark pool memory optimized of hardware accelerated is, het aantal gekozen nodes, en de grootte van die nodes.
Azure Synapse Analytics kosten:
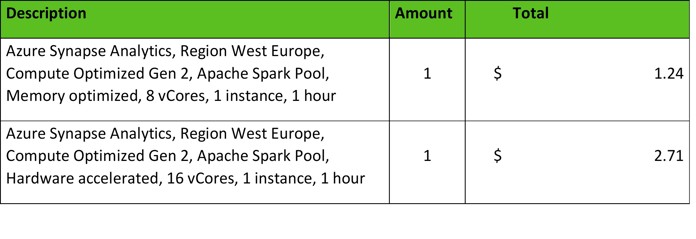
Voorbeeld Azure Synapse Analytics prijzen geschat op 25-03-2022. Voor de huidige prijslijst kan je de Pricing Calculator raadplegen.
Het belang van totale executiekosten
Na het lezen van deze informatie, zou je kunnen concluderen dat een Standard Tier Azure Databricks cluster de meest goedkope optie is... Huh? Is ons niet verteld dat Azure Databricks een van de duurdere opties is in het Azure universum? Deze stelling zou heel goed waar kunnen zijn. Zelfs met de bovengenoemde kosten. Maar, het zou ook net zo goed niet waar kunnen zijn.
Waarom is dat zo? Om een idee te krijgen van wat het daadwerkelijk kost om een data-applicatie te draaien, moet je niet alleen kijken naar de kosten per vCore/uur. Je moet ook rekening houden met andere factoren, zoals de uitvoeringstijd en het clustergebruik. Op Azure worden Apache Spark clusters namelijk niet gelijkwaardig gebouwd voor alle tools. Daarom zullen gelijke processen niet altijd even snel eindigen, en zullen ze ook niet evenveel resources gebruiken.
Uitvoeringstijd
ADF, Azure Databricks, en Azure Synapse Analytics gebruiken niet exact dezelfde versie als de Apache Spark die je kunt downloaden van de Apache Spark website. ADF, Azure Databricks, en Azure Synapse Analytics proberen allemaal de interne werking van Apache Spark op de een of andere manier te optimaliseren. Azure Databricks heeft bijvoorbeeld grondige documentatie over hun optimalisatie-inspanningen. Natuurlijk zijn alle tools verschillend geoptimaliseerd. Als gevolg daarvan zal exact hetzelfde proces nooit dezelfde uitvoeringstijd hebben. Dit zal uiteindelijk resulteren in variërende kosten.
Bovendien heeft men met ADF minder te zeggen over de manier waarop de data-applicaties worden uitgevoerd. Dit is vanwege de aard van de GUI. De GUI maakt het optimaliseren van processen moeilijker, wat mogelijk resulteert in hogere uitvoeringstijden.
Op dit moment lijkt de algemene consensus te neigen naar Azure Databricks als het gaat om de meest effectieve optimalisatie van Apache Spark. Echter, of dit voor jouw oplossing ook geldt, en hoeveel het verschil in uitvoeringstijd zal zijn, zal sterk afhangen van het type dataverwerking dat je applicatie uitvoert.
Cluster gebruik
Een andere factor die kosten beïnvloed is cluster gebruik. Azure Databricks en Azure Synapse Analytics bieden de mogelijkheid om het minimale en maximale aantal gewenste workers/executors in te stellen. Het aantal gebruikte workers/executors wordt dan dynamisch bepaald, afhankelijk van wat de tool nodig heeft om jouw data-applicatie draaien. Autoscaling kan helpen om kosten te besparen, omdat je alleen gefactureerd wordt voor de daadwerkelijke benodigde resources. ADF biedt op het moment van schrijven nog geen autoscaling.
Conclusie: een meer uitgebreide kijk op kosten
Hoewel een duidelijk inzicht in de kostenopbouw van een tool je kan helpen in het managen van kosten, is het niet alles. Op het gebied van uitvoeringskosten is het maken van een exacte schatting lastig. Er is een enorme hoeveelheid technische kennis nodig op het gebied van Apache Spark, het uit te voeren proces, en de werking van de gekozen tool nodig om een goede vergelijking te kunnen maken. In de realiteit is het exact berekenen en vergelijken van uitvoeringskosten meestal simpelweg een onmogelijke taak.
Je kan je afvragen of we ons überhaupt moeten richten op uitvoeringskosten. Op Azure is het gemakkelijk om je te verliezen in de technische details. Deze zoektochten zijn zeer zelden vruchtbaar. Wellicht is het beter om je op andere kosten te richten. Je zou bijvoorbeeld kunnen kijken naar de implementatie kosten van een dataproject. Deze kosten zullen onvermijdelijk een groot deel van de totale kosten uitmaken. Mogelijk zelfs een groter deel dan de uitvoeringskosten zelf.
Bijvoorbeeld: ben je bekend met .Net en wil je Apache Spark programmeren? In dat geval kan het implementeren van een Azure Databricks oplossing langer duren dan Azure Synapse Analytics, omdat Azure Databricks nog geen .Net ondersteuning biedt. Als je liever helemaal niet codeert, is de keuze voor ADF wellicht de slimste en meest kosteneffectieve optie.
Hoe nu verder?
Bent je geïnteresseerd om te weten wat ADF, Azure Databricks, Azure Synapse Analytics, of een combinatie van deze tools voor jouw bedrijf kan betekenen? Laat ons je helpen! Neem contact op met Intercept, en vraag naar een Data Deep dive of Data Design.