Vandaag de dag slaan bedrijven allerlei soorten gegevens op, zelfs als ze er nog geen doel voor hebben. Deze verandering heeft enerzijds te maken met een toename van de hoeveelheid data die wordt gecreëerd. Anderzijds is het nu ook daadwerkelijk mogelijk om al deze gecreëerde gegevens op te slaan. Dit komt door de relatief lage kosten van data opslag in vergelijking vroeger. Maar waar moeten al die verschillende soorten datasets worden opgeslagen? Dit is waar een 'Data Lake' om de hoek komt kijken!
In dit artikel bespreken we het volgende:
- Wat is een Data Lake?
- Data Lake Lagen: Brons, Zilver, en Goud
- 'The good' van het implementeren van Data Lake Layers
- 'The bad & the ugly' van de implementatie van Data Lake Layers
- Wanneer kan je het implementeren van een Data Lake overwegen?
1. Wat is een Data Lake?
In een Data Lake kan je alle soorten data opslaan die je maar kan bedenken. Het opslagformaat van de data en grootte maakt niets uit. Denk bijvoorbeeld aan het opslaan van CSV data en logs, of zelfs foto's en video's. Data kan naar het Data Lake worden geoffload als een stream of in een batch. Ook maakt het niet uit hoeveel data je in het Data Lake opslaat. Data Lakes zijn schaalbaar. Dit betekent dat ze in omvang toenemen naarmate gebruikers data uploaden. Afhankelijk van je use case kan een Data Lake slechts enkele honderden megabytes tot vele terabytes aan data bevatten.
Hoewel traditionele Data Lakes veel flexibiliteit bieden, is het juist deze flexibiliteit die de ondergang van het Data Lake kan betekenen. Naarmate gebruikers meer en meer data opslaan in het Data Lake, is het namelijk gemakkelijk om het overzicht over de inhoud te verliezen. Een groot aantal (ongedocumenteerde) datasets binnen het Data Lake zal het voor gebruikers moeilijk maken om datasets te vinden en te gebruiken. Moet er niet een meer gestructureerde aanpak komen voor het opslaan van data? Ja! Het implementeren van Data Lake Layers kan je helpen dit probleem in de kiem te smoren.
2. De verschillende Data Lake layers
Een layered Data Lake bevat drie soorten lagen: Brons, Zilver, en Goud:
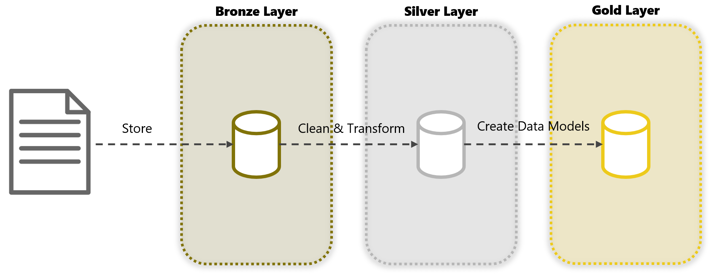
Bronzen laag: In deze laag worden gegevens opgeslagen in hetzelfde opslagformaat als in het bronsysteem.
Zilveren laag: Binnen deze laag worden opgeschoonde en getransformeerde gegevens opgeslagen. Denk bijvoorbeeld aan het correct opslaan van lege (null) waarden, het toepassen van naamgevingsconventies voor kolommen, en het bewaren van de gegevens in een geschikt opslagformaat (CSV/Parquet/JSON/etc.). Het is belangrijk om op alle datasets dezelfde standaarden toe te passen. Dit zorgt ervoor dat gebruikers begrijpen wat ze kunnen verwachten van de data in het Data Lake.
Gouden Laag: Binnen deze laag slaan we alle eindproducten op die geconsumeerd worden door klanten. Indien nodig worden verschillende datasets uit het Data Lake samengevoegd en/of geaggregeerd.
Opmerking: Het opstellen van een Bronzen, Zilveren en Gouden Laag sluit zeer goed aan bij de Data Journey fases geïntroduceerd in "Hoe transformeer je data in waardevolle informatie?". Data uit de Bronzen laag data wordt opgeslagen na Fase 1: Data Extractie. Gegevens van de Zilveren Laag worden opgeslagen na Fase 2: Data Transformatie en Opschoning. Data van de Gouden Laag wordt opgeslagen na Fase 3: Data Science en Analyse. Wanneer u deze vijf Data Journey stappen samen met een gelaagd Data Lake gebruikt, zal dit helpen om structuur aan te brengen in uw project. Ben je benieuwd naar het gebruiken van Data Lake Layers binnen je data journey? Neem contact met ons op om te ontdekken hoe we je kunnen helpen.
3. Data Lake Layers implementeren: The Good
Data Lake layers implementeren is een gestructureerde aanpak van je Data Lake, waardoor het voor gebruikers eenvoudiger wordt om de juiste datasets te vinden. Het implementeren van Data Lake Layers biedt ook meer voordelen , zoals:
Een veilige oplossing
Het gebruik van Data Lake lagen kan een beveiligingslaag toevoegen aan je oplossing. Gegeven dat de data in de Bronzen, Zilveren, en Gouden laag gescheiden wordt opgeslagen, zal het eenvoudiger worden om de juiste hoeveelheid toegang te verlenen aan de juiste mensen. Klanten krijgen bijvoorbeeld toegang tot de datasets in de Gouden laag. Data Engineers die voor de opslag van data zorgen, krijgen toegang tot de Bronzen laag.
Gemakkelijk geschiedenis bijhouden
Met een gelaagd Data Lake is het eenvoudiger om de geschiedenis van data bij te houden. Dit komt omdat deze op één plek wordt opgeslagen in de Bronzen Laag. Bovendien kan deze geschiedenis over een langere periode worden bewaard dan dat het in het bronsysteem wordt opgeslagen (zolang dit wettelijk is toegestaan, natuurlijk).
Het opslaan van historie kan ook van pas komen als er herberekeningen moeten worden gedaan. Denk bijvoorbeeld aan het aanpassen van bestaande code of het vinden van een bug. Omdat alle historie nu wordt opgeslagen in de Bronzen laag, kun je gemakkelijk de code opnieuw uitvoeren zonder afhankelijk te zijn van de retentietijd van het bronsysteem.
Dezelfde datasets gebruiken voor meerdere use cases
Het opslaan van data op een gecentraliseerde plek stelt gebruikers in staat om datasets gemakkelijker te vinden. Dit zal meerdere teams helpen om datasets te analyseren en te gebruiken voor verschillende doeleinden. Een voorwaarde hiervoor is wel dat de inhoud van het Data Lake goed gedocumenteerd moet zijn.
Hoge schaalbaarheid
Een Data Lake stelt je bedrijf in staat om elk type data op elke schaal op te slaan. Een Data Lake schaalt gemakkelijk op naarmate teams meer datasets opslaan. Dit resulteert in een flexibele oplossing (vooral in vergelijking met bijvoorbeeld een on-premise datawarehouse).
Toekomstbestendige dataoplossingen
Aangezien alle datasets in de Zilveren Laag aan dezelfde set standaarden voldoen, kunnen dataproducten die in de Gouden Laag zijn gemaakt relatief eenvoudig worden omgezet naar nieuwe databronnen. Deze aanpak maakt het onboarden van nieuwe datasets eenvoudiger.
4. Data Lake-lagen implementeren: the bad & the ugly
Er zijn verschillende factoren die je moet overwegen voordat je Data Lake Layers implementeert:
Het huidige kennisniveau
Het correct implementeren van een gelaagd Data Lake vereist een andere 'know how' dan je bijvoorbeeld voor een traditionele warehousing oplossing nodig hebt. Daarom is het van cruciaal belang dat gebruikers voldoende worden getraind in het gebruik van Data Lakes.
Data Lake of Data Moeras?
Voordat je een gelaagd Data Lake opzet, is het essentieel om eerst de spelregels op te stellen. Gebruikers van het Data Lake moeten weten hoe ze data moeten opslaan en hoe ze de inhoud ervan moeten documenteren. Bovendien moeten gebruikers begrijpen hoe ze de standaarden gezet in de Zilveren- en Gouden Laag moeten toepassen op de datasets. Als gebruikers zich niet houden aan de spelregels, dan wordt het steeds lastiger om goede datasets te vinden naargelang gebruikers data blijven uploaden.
5. Conclusie: Wanneer kan ik het implementeren van een Data Lake overwegen?
Ook al geloven wij in het gebruik van Data Lakes en denken we dat het gebruik ervan veel mogelijkheden met zich meebrengt, of de voordelen opwegen tegen de nadelen is aan jou! Vaak adviseren wij een gelaagd Data Lake wanneer bedrijven:
- Meerdere databronnen hebben en op zoek zijn naar een kosteneffectieve, schaalbare en structurele aanpak voor het opslaan van allerlei soorten (historische) data.
- Nog niet veel data opslaan, maar behoefte hebben aan een flexibele oplossing. Bijvoorbeeld, omdat ze verwachten in de toekomst meer data op te gaan slaan.
- Beschikken over data, maar hier nog geen use case voor gedefinieerd hebben.
Laten we beginnen!
Ben je benieuwd hoe de implementatie van Data Lake Layers uw bedrijf kan helpen? Met Intercept staan we altijd klaar om jouw data reis te beginnen! Stap in bij de Intercept trein en laat ons jouw gids zijn in data. We kunnen de hele datareis voor je verzorgen of slechts een paar stappen.
In 2022 lanceren we al onze datamogelijkheden. Ben je nieuwsgierig ? Neem dan alvast een kijkje en bekijk wat interessant voor jou is.