De populaire regio’s, beter bekend als “hero regions”, hebben vaak last van capaciteitsproblemen. Vooral de EU-West regio (de grootste hero region), een van Microsoft’s drukste datacenters, kampt hier al jaren mee.
Maar Azure West Europe is niet de enige regio die geraakt wordt; andere regio’s die soms problemen hebben zijn:
- (Europa) UK South
- (Noord-Amerika) Canada Central
- (Noord-Amerika) East US
- (Noord-Amerika) East US
Microsoft’s oplossing? Probeer een andere, minder drukke regio/zone; dat is wat de “behulpzame” support agent zegt…
Andere regio’s gebruiken kan een tijdelijke oplossing zijn voor je Azure-omgeving, maar dit kan ook een groot probleem worden omdat:
- Niet elke cloudarchitectuur flexibel genoeg is om snel nieuwe regio’s te gebruiken
- Je bepaalde features nodig hebt, en niet elke regio biedt dezelfde features (nog)
- Je cloudbudget het niet toelaat om te verhuizen; sommige regio’s zijn duurder dan andere
- Azure Governance en policies vereisen dat je in de “geraakte” regio moet deployen
Bij Intercept werken we bijvoorbeeld vooral met Nederlandse klanten (Azure West Europe) die niet zomaar kunnen uitwijken naar een andere regio door compliance-eisen.
Veel landen en sectoren eisen dat data binnen bepaalde grenzen blijft, en als je die regels breekt kan dat leiden tot boetes of beperkingen. Als een klant verplicht in een bepaalde regio moet deployen en dan te horen krijgt dat ze moeten uitwijken naar bijvoorbeeld Azië of de VS, letterlijk aan de andere kant van de wereld, dan is hun reactie vaak: “Serieus??”
Het punt is: dit werkt niet altijd. Daarom zijn er wat workarounds nodig.
Oplossingen
Totdat de capaciteitsproblemen echt voorbij zijn, moet je het risico zoveel mogelijk beperken.
1. Geen autoscaling meer
Autoscaling wordt vaak gebruikt om kosten te besparen door dynamisch compute-instances toe te voegen of te verwijderen op basis van de vraag. Maar in tijden van onzekerheid kan autoscaling riskant zijn.
Denk erover na: als je stopt-dealloceert, geef je je capaciteit op. Het idee is om geld te besparen tijdens rustige momenten, maar dit kan je later juist schaden.
Bij schaarste is het slimmer om je capaciteit vast te houden en autoscaling uit te zetten. Laat je resources gewoon draaien in plaats van te gokken of er straks nog plek is.
2. On-Demand Capacity Reservations
Met het on-demand capacity reservation programma van Microsoft kun je compute-capaciteit reserveren in een Azure-regio of availability zone. Je reserveert en betaalt de VM vooraf om de capaciteit te garanderen op het moment dat je die nodig hebt. Zo voorkom je allocatieproblemen en verhoog je uptime.
Bij verwachte pieken, zoals tijdens een migratie, of bij bedrijfskritische workloads is dit het overwegen waard.
Een klant overtuigen om weken van tevoren al voor compute te betalen is niet makkelijk. Maar wil je echt het risico lopen op mislukte deployments, productiviteitsverlies of downtime?
3. Resize je VMs
Het is verleidelijk om de nieuwste SKUs te gebruiken, die snellere processors beloven. Maar niet elke workload heeft dat nodig. Nieuwe SKUs draaien vaak op de nieuwste hardware, en daar zijn de tekorten meestal het grootst.
Kies liever een VM-size die past bij je werkelijke workload. Kleinere of middelgrote SKUs, zoals D_v3, draaien op meer verschillende hardware, waardoor je meer kans hebt dat Azure ze kan alloceren. Dit geldt ook voor andere resources, want bijna elke Azure-service draait uiteindelijk op VMs.
4. Vermijd legacy VM-sizes
Legacy VM-series (Av1, Dv1, DSv1, D15v2, DS15v2, enz.) draaien niet op de nieuwste hardware. Als je die nog gebruikt, loop je kans op allocatiefouten, zelfs als er wel nieuwere VMs beschikbaar zijn.
De oplossing is migreren naar nieuwere VMs. Die zijn geoptimaliseerd voor de huidige hardware, presteren beter en zijn vaak ook gunstiger geprijsd.
5. Overweeg meerdere regio’s
Als je alles in één regio draait, beperkt dat je schaalbaarheid en flexibiliteit. En als die regio een hero-region is, heb je extra kans op tekorten.
Als je regelgeving, data-eisen en governance het toelaten, overweeg dan multi-region deployments voor schaalbaarheid, compliance en resilience.
In Azure zijn er regio pairs: elke regio heeft een peer-regio, wat het gemakkelijker kan maken om een oplossing voor meerdere regio's te overwegen.
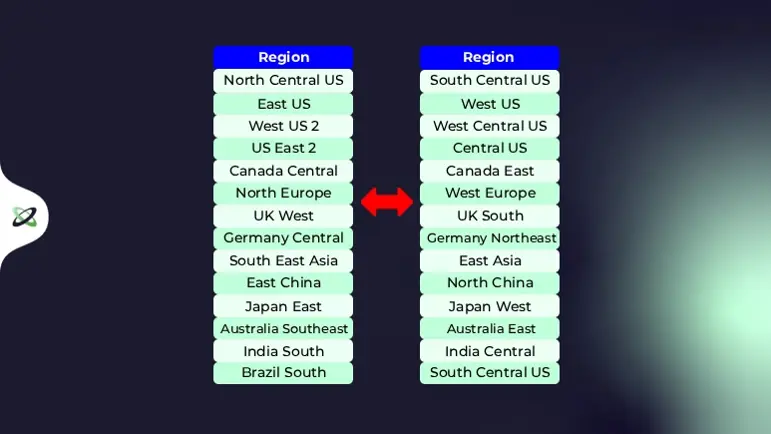
- Elke Azure-regio is gekoppeld aan een andere regio binnen hetzelfde geografische gebied.
- Deze regio's liggen doorgaans minstens 300 mijl uit elkaar.




