In this article, we will take a deep dive into the costs of three frequently used tools on Azure that utilize Apache Spark:
- Azure Data Factory
- Azure Databricks
- Azure Synapse Analytics
First, we will explain these tools and how they utilize Apache Spark. Then, we will further elaborate on the pricing of these tools, finally putting the age-old question of which tool is most expensive to bed.
Note: All costs estimated in this article are based on the Azure Pricing calculator.
The Pricing Calculator is a free service offered by Microsoft to help you gain insights into pricing.
What is Apache Spark?
Apache Spark can be installed and run on any computer. However, in the cloud, we usually rely on clusters to provide applications with the necessary computational power. On Azure, Apache Spark can be run using a multitude of tools, including Azure Data Factory, Azure Databricks, and Azure Synapse Analytics.
Are you interested in knowing when to start coding Apache Spark yourself, instead of using a GUI? You can find more information in this article called “Data Factory vs. Databricks: When your love for data is missing some (Apache) Spark."
Azure Data Factory: a breakdown
Azure Data Factory (ADF) is a fully managed, serverless data integration service. ADF can be used for ingesting and transforming data sources by using a Graphical User Interface (GUI). Out of the box, ADF can connect to over 90 already built-in data sources. These data sources can be easily configured by hand within the GUI. ADF offers multiple options, but it’s the Data Flows that Utilize Apache Spark.
ADF Data Flows
Data Flows are used within ADF to visually design data transformations. Data Flows come in handy for users who want to utilize the powers of Apache Spark but don’t want or know how to code.
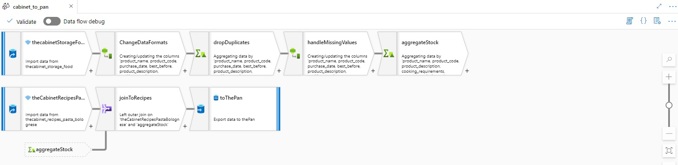
Example of a Data Flow
Data Flows run on a so-called Data Flow Runtime. It’s the Data Flow runtime that provides the computational power to execute Apache Spark. Data Flow runtimes come in two different flavors: General Purpose and Memory Optimized. General Purpose clusters are good for general use cases. Memory-optimized runtimes offer the best performance, making them suitable for large datasets.
ADF pricing:
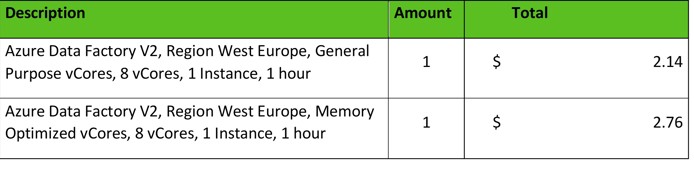
An example of ADF pricing estimated on 25-03-2022. For current pricing, please consult the Pricing Calculator.
Note: Other operations like Read/Write operations and Monitoring operations are priced separately in ADF. This means that actual costs will be higher than depicted above.
Azure Databricks: a breakdown
Azure Databricks will help you solve Data Science, Data Engineering, Machine Learning, and Business Intelligence use cases. Instead of configuring Data Flows by hand within a GUI as you would do with ADF, Azure Databricks enables its users to write Apache Spark code themselves. Apache Spark is run on customizable clusters that attach to so-called notebooks. Clusters are the brains of the operation, offering computation resources and configurations to run Apache Spark. Azure Databricks supports multiple languages like Python, Scala, R, Java, and SQL.
Azure Databricks Notebooks
A notebook is a web-based interface in which a user writes code. Apache Spark Code is placed within so-called cells.
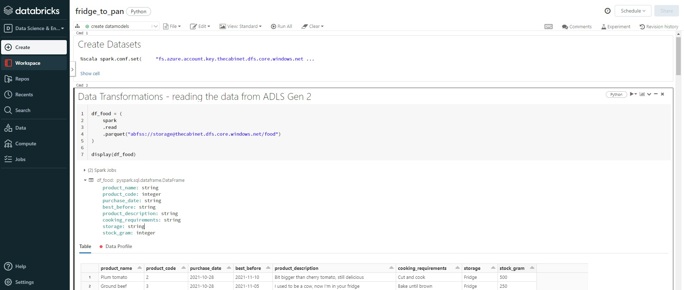
Example Azure Databricks notebook
When creating a cluster, a user has many options to choose from. As you can imagine, all options are priced slightly differently. To make pricing a little bit easier, Azure Databricks prices their clusters per Databricks Unit (DBU). As Microsoft puts it: “A DBU is a unit of processing capability, billed on a per-second usage. The DBU consumption depends on the size and type of instance running Azure Databricks”. Settings that will have an impact on the DBU usage include whether the instance deployed is Standard of Premium, the number of Workers, the Worker -, and Driver type. More information on cluster configuration can be found here.
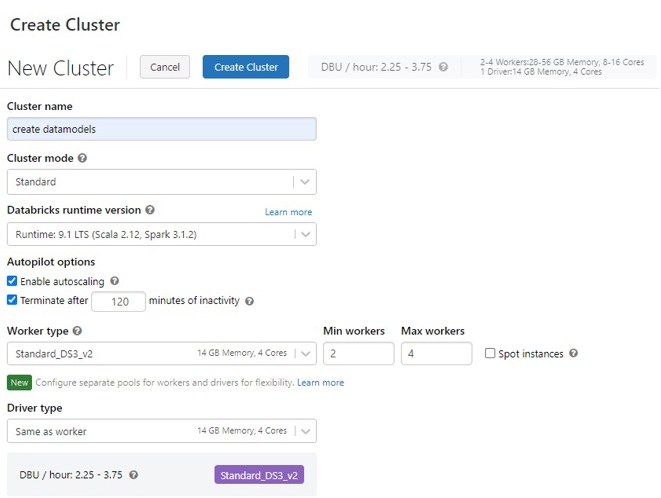
Example Azure Databricks cluster
Azure Databricks pricing:
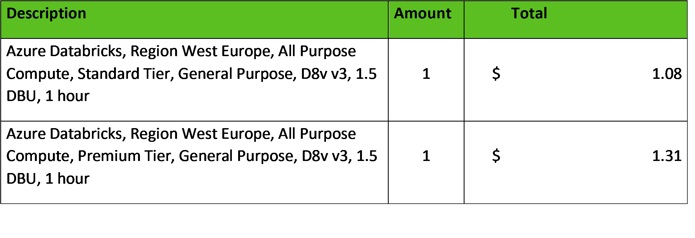
Example Azure Databricks pricing estimated on 25-03-2022. For current pricing, please consult the Pricing Calculator.
Azure Synapse Analytics: A breakdown
Azure Synapse Analytics, previously known as Azure SQL Data Warehouse, is much more than just your ordinary SQL data warehouse. This comprehensive enterprise analytics service brings together Apache Spark for big data analytics, dedicated and serverless SQL pools for your data warehouse, Data Explorer for log and time series analysis, and Pipelines for ETL/ELT processes. Azure Synapse Analytics utilizes Apache Spark in both Pipelines and Spark pools. Azure Synapse Analytics supports multiple languages like Python, Scala, .NET, and Spark SQL.
Note: given the similarities in functionality and cost between Azure Synapse Analytics Pipelines and ADF Data Flows, this article will not cover Azure Synapse Analytics Pipelines.
Azure Synapse Analytics Notebooks
A notebook within Azure Synapse Analytics is, like Azure Databricks notebooks, a web-based interface. Within a notebook, a user can create cells in which to place Apache Spark code. This code can be run after attaching a Spark Pool. Spark Pools are the brains of the operation, offering computation resources and configurations to run Apache Spark.
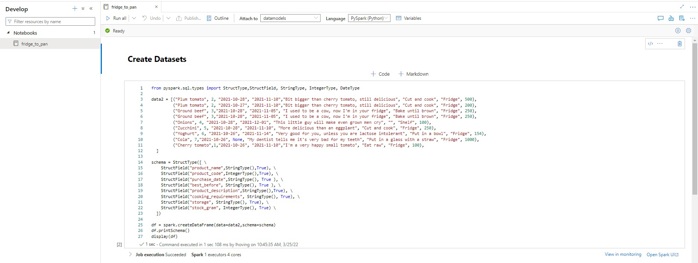
Example Azure Synapse Analytics notebook
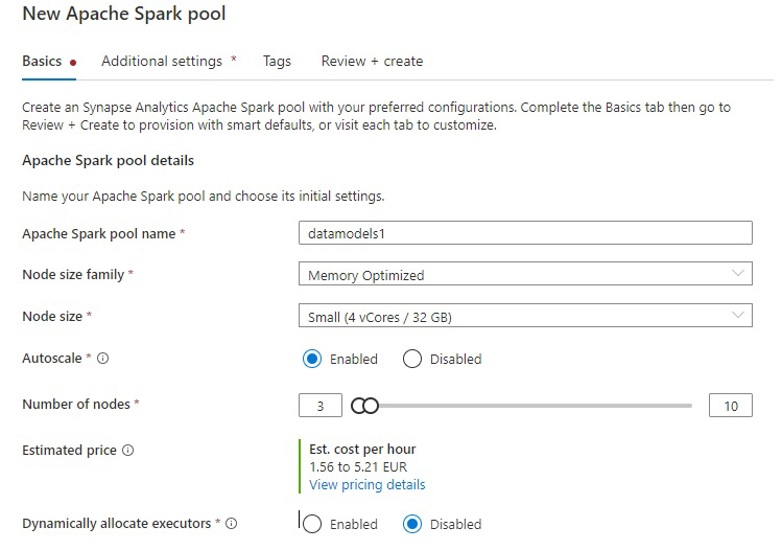
The process of creating Spark Pools is similar to creating Azure Databricks clusters. Overall, the user has a little bit less options to choose from compared to Azure Databricks. For example, a user can choose to use either Apache Spark 3.1 or 2.4 in Azure Synapse Analytics. Azure Databricks offers more options ranging from 3.2.1 to 2.4.5. Settings that will have an impact on costs include whether the pool is memory-optimized of hardware accelerated the node size and the number of nodes.
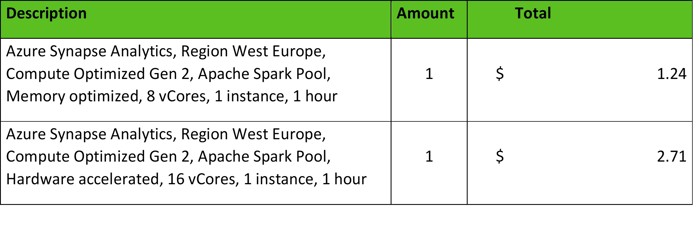
Azure Synapse Analytics Pricing:
The importance of total execution costs
After reading this information, one might take away that a Standard Tier Azure Databricks cluster is the most cost-effective option… Wait what? Haven’t we all been told that Azure Databricks is one of the more expensive options in the Azure universe? This might very well be true, or not true at all.
Why? To get a grasp on what it will cost to run a data application, one cannot solely look at the costs per vCore/hour. You must take other factors, like execution time and cluster utilization into account as well. On Azure, Apache Spark clusters are not created equally throughout tools. Therefore, equal processes will not finish equally fast, nor will they utilize the same number of resources.
Execution time
ADF, Azure Databricks, and Azure Synapse Analytics don’t use the Apache Spark that you can download from the Apache Spark website. Instead, these tools try to optimize the inner workings of Apache Spark in one way or the other, adding their custom layer to it. For example, Azure Databricks has thorough documentation on how their optimization efforts are implemented. Of course, all tools are optimized differently. As a result, the exact same process will never have the same execution time throughout tools. This will ultimately result in varying costs.
In addition, using ADF, one will have less say in how data applications are executed on the Data Flow runtime due to the nature of the GUI. This makes optimizing processes more difficult for ADF users, potentially resulting in higher execution times and costs.
Note: At the moment of writing, general consensus seems to be that Azure Databricks is overall better optimized than ADF and Azure Synapse Analytics. However, whether this is true for your use case, and how much the difference in execution time will be will heavily depend on the type of data processing your application executes.
Cluster Utilization
Another factor that affects costs is cluster utilization. Azure Databricks and Azure Synapse Analytics offer the option to list the minimum and maximum used workers/executors. Throughout your data application, these tools will scale up or down depending on the resources needed. Automatic scaling can help to save costs, as you are only billed for the necessary resources. ADF does not offer autoscaling, yet.
Conclusion: a more comprehensive look at costs
Even though understanding how prizing works on Azure can help in preventing any unwanted surprises, making an exact estimation of execution costs will take an enormous amount of technical knowledge on Apache Spark, the to-be-executed process, and the inner workings of the chosen tool. In real life, calculating and comparing execution costs before starting a project is just an impossible task.
Then, should we focus on execution costs at all? On Azure, it’s easy to go down the rabbit hole, losing yourself in the technical details of it all. These quests are very rarely fruitful. Therefore, you might be better off focusing on other costs that make up a project’s total costs. For example, one could look at the costs of implementing and maintaining a data application. These costs will inevitably make up a large chunk of the total costs. Possibly even a bigger portion than the execution costs.
For example: are you acquainted with .Net and want to program Apache Spark? In that case, it might take longer to get acquainted with Azure Databricks compared to Azure Synapse Analytics, given that Azure Databricks does not offer .Net support. If you prefer not to code, going with ADF might be the smartest and most cost-effective option.
How to continue?
Are you interested in knowing what ADF, Azure Databricks, Azure Synapse Analytics, or a combination of these tools can mean for your company? Have us help! Contact Intercept, and ask about a Data Deep dive or Data Design.