This "think before you store" attitude has shifted to "store before you think". Today, companies save all kinds of data, even when they don’t yet have a use case for it. This mentality shift has to with an increase in the amount of data being created on the one hand. On the other hand, given that storage costs have been steadily decreasing over the years, it is now actually possible to store all this created data. But where should all these different types of datasets be stored? This is where the Data Lake comes in!
In this article we discuss:
- What is a Data Lake?
- Data Lake Layers: Bronze, Silver, and Gold
- The Good of Implementing Data Lake Layers
- The Bad and Ugly of Implementing Data Lake Layers
- When to Implement a Data Lake
1. What is a Data Lake
In a Data Lake, you can store all kinds of datasets regardless of their format and size. Think for example of storing CSV data and logs, or even pictures and videos. Data can be offloaded to the Data Lake as a stream or in batch. In addition, it shouldn't matter how much data you want to store. Data Lakes are scalable, increasing in size as users upload data. Depending on your use case, a Data Lake can contain only a few hundreds of megabytes up to many terabytes of data.
Even though traditional Data Lakes offer much flexibility, it's this flexibility that may very much mean its downfall. Namely, as users save more and more data to the Data Lake, it's easy to lose track of its contents. A large number of (undocumented) datasets within the Data Lake will make it difficult for users to find and use datasets. Shouldn't there be a more structured approach to storing data? Yes! Implementing Data Lake Layers can help you mitigate this problem
2. Different Data Lake layers
A layered Data Lake uses three layers: Bronze, Silver, and Gold:
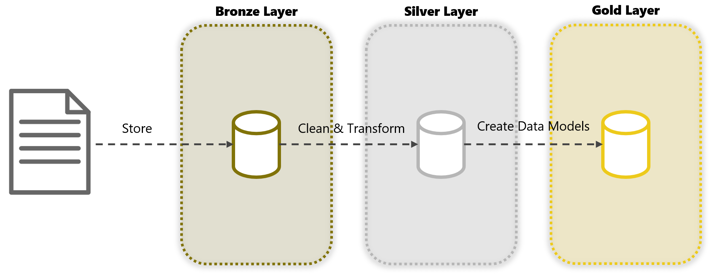
Bronze Layer: Within this layer, data is stored in the same format as it exists within the source system.
Silver Layer: Within this layer, cleaned and transformed data is stored. For example, consider handling empty (null) values, setting column naming conventions, and keeping the data in a suitable format (CSV/Parquet/JSON/etc.). It’s important to apply the same standards throughout datasets in the Silver Layer, as this ensures that users understand what to expect from the data in the Data Lake.
Gold Layer: We store all (customer-facing) end products within this layer. If required, datasets are joined together and/or aggregated.
Note: The Bronze-, Silver-, Gold Layer approach maps very well to the data journey phases introduced in "How to Transform Data into Valuable Information?". Bronze Layer data is stored after Phase 1: Data Extraction. Silver Layer data is stored after Phase 2: Data Transformation and Cleaning. Gold Layer Data is stored after Phase 3: Data Science and Analysis. When using these five data journey steps together with a layered Data Lake approach will help to bring structure to your project. Are you curious to start using Data Lake Layers within your data journey? Contact us to find out how we can help.
3. Implementing Data Lake Layers: The Good
Data Lake Layers will offer a structured approach to your Data Lake, making it easier for users to find the correct dataset for the job. Implementing Data Lake Layers will also provide more benefits, like:
A more secure solution
Utilizing Data Lake layers can add a layer of security to your solution. Given that Data Lake Layers separate Bronze Layer (raw) data, Silver Layer (intermediate) data, and Gold Layer (customer-facing) data, it becomes easier to grant the right amount of access to the right people. For example, customers are given access to the Gold Layer datasets. Meanwhile, engineers that take care of storing data are granted access to the Bronze Layer.
Easily keep track of history
Using a layered Data Lake approach makes it easier to keep track of your history, as it is stored in one place within the Bronze Layer. In addition, this history can be retained over a longer period than the source system does (as long as this is permitted by law, of course).
Storing history can also come in handy when recalculations need to be done. Think, for example of adjusting existing code or finding a bug. Given that your company stores the source datasets to the Bronze Layer, it's now possible to rerun your code without being dependent on the retention time of the source system.
Using the same datasets for multiple use cases
Assuming that the Data Lake’s content is documented properly, storing data in a centralized place will enable users to find datasets more easily. This will help multiple teams to analyze and use your valuable datasets for various use cases.
High scalability
A Data Lake enables your company to store any type of data at any size. A Data Lake scales easily as teams onboard more datasets, resulting in a flexible solution (especially compared to an on-premise data warehouse).
Future proof designs
Given that all datasets in the Silver Layer adhere to the same set of standards, data products created in the Gold Layer can be relatively easily pointed to new data sources. This approach makes the onboarding of new datasets easier
4. Implementing Data Lake Layers: the Bad and the Ugly
There are several factors to consider before implementing Data Lake Layers:
Having the expertise in-house
Correctly implementing Data Lake Layers requires different know-how than a traditional warehousing solution. Therefore, it is crucial that users are adequately trained on using Data Lake Layers before implementing them.
Data Lake or Data Swamp?
Before even setting up Data Lake Layers, it is essential to create rules of play. Users need to know how to store data in the Data Lake Layers and how to document its contents. In addition, they need to understand how to adhere to Silver- and Gold Layer standards. If users don't know how to play by the rules, it will become increasingly difficult to use the Data Lake as it grows bigger and bigger.
5. Conclusion: When to Implement a Data Lake
Even though we believe that using Data Lake Layers brings many opportunities, whether the pros outweigh the cons is up to you! Often, we advise a layered Data Lake approach to companies that:
- Have multiple data sources and are looking for a cost-effective, scalable and structural approach to storing all kinds of (historical) data.
- Don’t store much data yet, but are in need of a flexible solution as they expect to onboard more datasets in the future.
- Have data but don't yet have a use case defined for it.
Let’s start!
Are you curious to learn how implementing Data Lake Layers can help your company? With Intercept, we are always ready to start your data journey! Hop on the Intercept train and let us be your guide in data. We can take care of your entire data journey or just a few phases.
In 2022 we will launch all our data possibilities. Are you curious to start? Check our out possibilities for you.